
網頁信息收集器
v1.0- 軟件大小:1.04 M
- 軟件語言:簡體中文
- 更新時間:2024-01-18
- 軟件類型:國產軟件 / 網頁輔助
- 運行環境:WinXP, Win7, Win8, Win10, WinAll
- 軟件授權:免費軟件
- 官方主頁:http://www.jlass.com.cn
- 軟件等級 :
- 軟件廠商:暫無
- 介紹說明
- 下載地址
- 精品推薦
- 相關軟件
- 網友評論
網頁信息收集器是一款綠色小巧,功能實用的網頁信息采集軟件。Internet上有著極其龐大的資源信息,各行各業的信息無所不有,網頁信息收集器可以很方便的針對某個網站的信息內容進行收集。如某個論壇的所有注冊會員的E-MAIL列表、某個行業網站的企業名錄、某個下載網站上所有軟件列表等等。操作簡單方便,更容易為普通用戶所掌握,有需求的用戶不妨下載體驗!
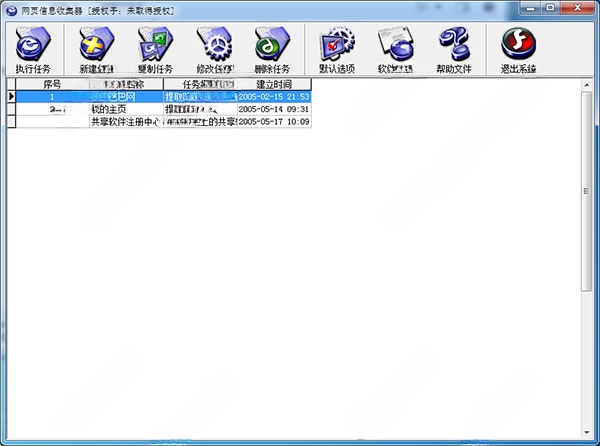
根據已建立的任務信息保存、提取網頁,也可通過“雙擊”某項任務啟動此功能
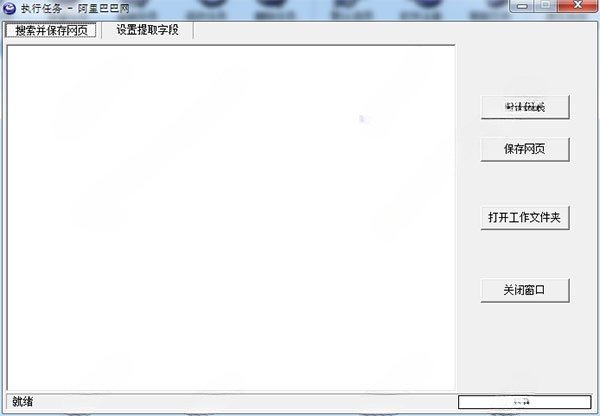
2、新建、復制、修改、刪除任務
新建、復制、修改、刪除任務信息
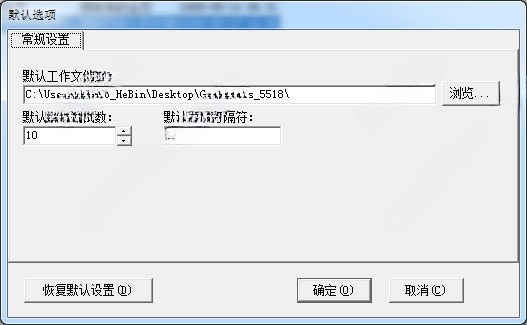
3、默認選項
設置默認工作路徑(默認為當前程序目錄下的WorkDir文件夾)
設置默認提取測試數 (默認為10)
設置默認文本分隔符 (默認為 *)
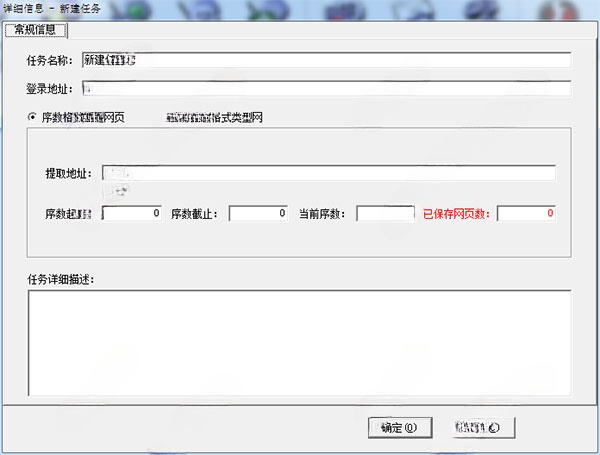
4、新建、編輯任務信息
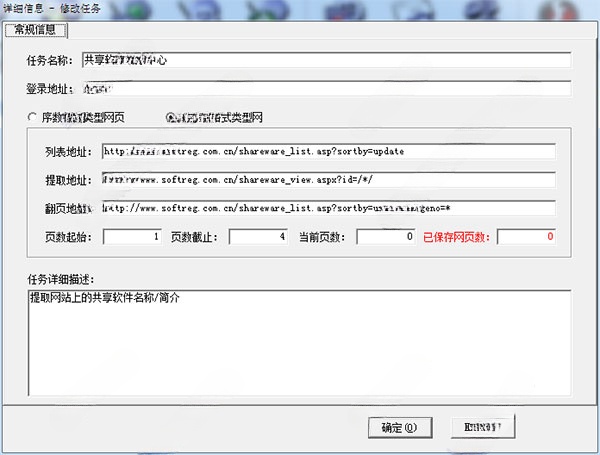
任務名稱:在默認的工作文件夾下生成以此命名的文件夾。
登錄地址:針對某些需要登錄才能查看其網頁內容的網站,填寫登錄頁面地址。在執行任務時,軟件會打開此登錄頁面讓您登錄該網站
序數格式類型網頁、非序數格式類型網:
這里的序數格式、非序數格式主要是指提取地址是否僅僅是數字的變化。例如類似于:
①http://xxx.com/1.html 和 http://xxx.com/2.html 就屬于序數格式
②http://xxx.com/abc.html 和 http://xxx.com/def.html 則屬于非序數格式
列表地址:在類型為“非序數格式類型網”時,第一頁列表的鏈接地址
提取地址:由實際保存的網頁地址共同部分 + * 號組成。
例如要提取:
①http://xxx.com/1.html 和 http://xxx.com/2.html 則提取地址為 http://xxx.com/*.html
②http://abc.xxx.com/abc.html 和 http://test.xxx.com/def.html 則提取地址為 http://*.xxx.com/*.html
翻頁地址:為列表網頁上的“下一頁”鏈接地址,將其中變化的部分用 * 號代替。
頁數起始:要開始提取的頁數
頁數截止:要停止提取的頁數
當前頁數:當前已經提取到的頁數
已保存網頁數:已經保存的網頁數
任務詳細描述:該任務的詳細描述信息
功能特色
1、執行任務根據已建立的任務信息保存、提取網頁,也可通過“雙擊”某項任務啟動此功能
2、新建、復制、修改、刪除任務
新建、復制、修改、刪除任務信息
3、默認選項
設置默認工作路徑(默認為當前程序目錄下的WorkDir文件夾)
設置默認提取測試數 (默認為10)
設置默認文本分隔符 (默認為 *)
4、新建、編輯任務信息
任務名稱:在默認的工作文件夾下生成以此命名的文件夾。
登錄地址:針對某些需要登錄才能查看其網頁內容的網站,填寫登錄頁面地址。在執行任務時,軟件會打開此登錄頁面讓您登錄該網站
序數格式類型網頁、非序數格式類型網:
這里的序數格式、非序數格式主要是指提取地址是否僅僅是數字的變化。例如類似于:
①http://xxx.com/1.html 和 http://xxx.com/2.html 就屬于序數格式
②http://xxx.com/abc.html 和 http://xxx.com/def.html 則屬于非序數格式
列表地址:在類型為“非序數格式類型網”時,第一頁列表的鏈接地址
提取地址:由實際保存的網頁地址共同部分 + * 號組成。
例如要提取:
①http://xxx.com/1.html 和 http://xxx.com/2.html 則提取地址為 http://xxx.com/*.html
②http://abc.xxx.com/abc.html 和 http://test.xxx.com/def.html 則提取地址為 http://*.xxx.com/*.html
翻頁地址:為列表網頁上的“下一頁”鏈接地址,將其中變化的部分用 * 號代替。
頁數起始:要開始提取的頁數
頁數截止:要停止提取的頁數
當前頁數:當前已經提取到的頁數
已保存網頁數:已經保存的網頁數
任務詳細描述:該任務的詳細描述信息
下載地址
- Pc版




















網友評論