
尚書7號ocr文字識別最新版
v7.0官方正式版- 軟件大小:44.45 MB
- 軟件語言:簡體中文
- 更新時(shí)間:2024-02-05
- 軟件類型:國產(chǎn)軟件 / 文字處理
- 運(yùn)行環(huán)境:winall/win7/win10/win11
- 軟件授權(quán):免費(fèi)軟件
- 官方主頁:http://www.jlass.com.cn
- 軟件等級 :
- 軟件廠商:暫無
- 介紹說明
- 下載地址
- 精品推薦
- 相關(guān)軟件
- 網(wǎng)友評論
 尚書7號ocr文字識別官方版是款專業(yè)性很強(qiáng)而且使用范圍也很廣泛的文字識別系統(tǒng),尚書7號ocr文字識別最新版應(yīng)用OCR技術(shù),為滿足書籍、報(bào)刊雜志、報(bào)盤票據(jù)、公文檔案等錄入需求,實(shí)現(xiàn)系統(tǒng)管理方式而設(shè)計(jì)的軟件系統(tǒng),本軟件系統(tǒng)正是適用于個人、小型圖書館、小型檔案館、小型企業(yè)進(jìn)行大規(guī)模文檔輸入,圖書翻印、大量資料電子化的軟件系統(tǒng)。
尚書7號ocr文字識別官方版是款專業(yè)性很強(qiáng)而且使用范圍也很廣泛的文字識別系統(tǒng),尚書7號ocr文字識別最新版應(yīng)用OCR技術(shù),為滿足書籍、報(bào)刊雜志、報(bào)盤票據(jù)、公文檔案等錄入需求,實(shí)現(xiàn)系統(tǒng)管理方式而設(shè)計(jì)的軟件系統(tǒng),本軟件系統(tǒng)正是適用于個人、小型圖書館、小型檔案館、小型企業(yè)進(jìn)行大規(guī)模文檔輸入,圖書翻印、大量資料電子化的軟件系統(tǒng)。
軟件功能
1、識別字符簡體字符集:國標(biāo)GB2312-80的全部一、二級漢字6800多個。
2、純英文字符集。
3、簡繁字集:除了簡體漢字外,還可以混識臺灣繁體字5400多個以及香港繁體字和GBK漢字。
4、識別字體種類能識別宋體、仿宋、楷、黑、魏碑、隸書、圓體、行楷等一百多種字體,并支持多種字體混排。
5、識別字號初號 小六號字體。
6、表格識別可以自動判斷、拆分、識別和還原各種通用型印刷體表格。
7、可支持繁體WINDOWS系統(tǒng)。
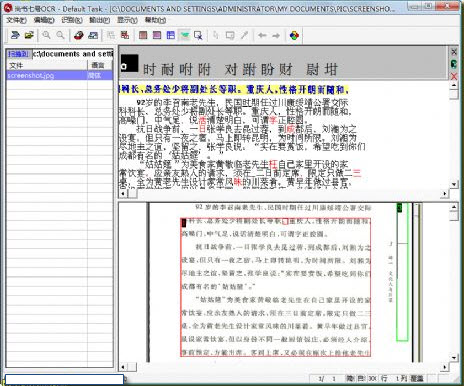
使用方法
1.如果用戶從光盤上復(fù)制圖像及數(shù)據(jù)進(jìn)行進(jìn)行處理,務(wù)必先將這些文件的只讀屬性去掉。
2.處理純英文文檔時(shí),識別語言選項(xiàng)設(shè)定為“簡體”、“簡繁”、“英文”都可以,但設(shè)定為“英文”識別效果最好;當(dāng)處理含有繁體字的文檔時(shí),語言選項(xiàng)應(yīng)設(shè)定為“簡繁”。
3.如果表格結(jié)構(gòu)因?yàn)閿嗑€而識別錯誤,可以先用工具按鈕中的畫筆在圖像上彌補(bǔ)斷線再重新版面分析
識別效果不佳的原因
1. 掃描設(shè)置不當(dāng),掃描圖像時(shí)的掃描分辨率(Resolution)一般應(yīng)設(shè)為300dpi,如果文檔字體較小則需要將掃描分辨率設(shè)定為更高值如400dpi或600dpi。縮放比例(Scaling)設(shè)為100%,亮度閥值(Threshold,Brightness)需根據(jù)紙張和印刷的質(zhì)量調(diào)節(jié),避免掃描圖像過黑或過淡 。
2. 如自動版面分析有錯誤,這時(shí)請用戶用鼠標(biāo)自己劃分出正確的版面塊;版面塊的版式設(shè)置錯誤,如將橫版的設(shè)置為豎版,豎版的設(shè)置為橫版等,這時(shí)請用戶自行將塊的版式修改正確。
3.原稿印刷質(zhì)量太差,筆畫斷裂嚴(yán)重、油墨太濃、字與字之間粘連嚴(yán)重等也可能使識別率顯著降低。
4.識別語言選項(xiàng)選擇不當(dāng),應(yīng)根據(jù)原稿正確選擇“簡體”、“簡繁”或“英文”
FAQ
1、尚書7號ocr文字識別系統(tǒng)中出現(xiàn)綠色的框是怎么回事?
“可以把掃描上的文字直接用于編輯”與掃描儀無關(guān),什么掃描儀都可以。能“直接用于編輯”屬于漢字識別,是靠OCR(光學(xué)字符識別)軟件實(shí)現(xiàn)的。
2、尚書七號ocr破解版怎么提取文字?
你只需要在打開的文檔中用鼠標(biāo)選中你想提取的目標(biāo)文字,然后修改識別框的屬性,即——橫排、豎排、表格、圖片這四種。然后識別就可以了。最后選擇輸出就可以了。
3、識別效果不佳的原因?
①掃描設(shè)置不當(dāng),掃描圖像時(shí)的掃描分辨率(Resolution)一般應(yīng)設(shè)為300dpi,如果文檔字體較小則需要將掃描分辨率設(shè)定為更高值如400dpi或600dpi。縮放比例(Scaling)設(shè)為100%,亮度閥值(Threshold、Brightness)需根據(jù)紙張和印刷的質(zhì)量調(diào)節(jié),避免掃描圖像過黑或過淡 。
②如自動版面分析有錯誤,這時(shí)請用戶用鼠標(biāo)自己劃分出正確的版面塊;版面塊的版式設(shè)置錯誤,如將橫版的設(shè)置為豎版,豎版的設(shè)置為橫版等,這時(shí)請用戶自行將塊的版式修改正確。
③原稿印刷質(zhì)量太差,筆畫斷裂嚴(yán)重、油墨太濃、字與字之間粘連嚴(yán)重等也可能使識別率顯著降低。
④識別語言選項(xiàng)選擇不當(dāng),應(yīng)根據(jù)原稿正確選擇“簡體”、“簡繁”或“英文”。
下載地址
- Pc版




















網(wǎng)友評論